Sentimen analysis atau disebut juga opinion mining biasanya diterapkan pada ulasan, tanggapan survei, media online dan sosial. Tujuannya adalah untuk menilai sikap atau reaksi pembaca, pembicara, pemakai aplikasi terhadap suatu produk atau berita atau dokumen. Intinya untuk menilai reaksi pelanggan apakah itu baik, buruk, atau netral.
Pengklasifikasian Sentiment Analysis
-
Machine Learning
Pendekatan ini memakai teknik machine learning dan berbagai fitur untuk
membuat pengklasifikasi yang dapat mengidentifikasi teks yang mengekspresikan
suatu sentimen. Metode deep learning sekarang sedang populer karena cocok untuk
mempelajari data
-
Lexicon-based
Metode ini menggunakan berbagai macam kata yang dianotasikan oleh skor untuk
menentukan penilaian secara umum dari konten yang diberikan. Aset terbaik dari
teknik ini adalah teknik ini tidak membutuhkan data untuk latihan, sementara
kelemahannya adalah banyak kata dan ekspresi yang tidak dimasukkan dalam
sentimen lexicon
-
Hybrid
Gabungan dari machine learning dan lexicon-base. Walaupun jarang digunakan
metode ini biasanya menghasilkan hasil yang lebih menjanjikan dibandingkan
kedua metode diatas.Untuk contoh kasus kita akan mencoba program untuk mengumpulkan kata-kata yang sering digunakan pada komentar facebook yang berbau SARA tapi belum diklasifikasikan apakah kalimat yang dibentuk termasuk positif atau negatif. Caranya:
Pertama kita perlu mempersiapkan beberapa hal:
o R
dan Rstudio
Kita bisa mendownload R dan R studio di https://cran.r-project.org/bin/windows/base/
dan https://www.rstudio.com/products/rstudio/download/
o Akun
facebook developer
Kita dapat membuat akun facebook developer di https://developers.facebook.com/
o Token
Akses dari Penjelajah API Graf
Kita bisa mendapatkan token akses dari API Graph
Explorer dengan cara pada https://developers.facebook.com/
pilih Alat & Dukungan, pilih Penjelajah API Graf kemudian akan muncul
tampilan seperti ini

Pilih dapatkan token dan izinnya dipilih semua
dan pilih dapatkan token akses
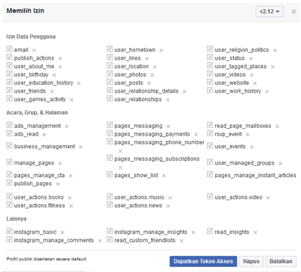
Kemudian kita perlu simpan token akses yang
dihasilkan (*Token Akses ini hanya berlaku sampai 2 jam, lebih dari itu perlu
membuatnya lagi.)
Kemudian kita jalankan Rstudio dan ketikkan
install.packages("devtools")
install.packages("plyr")
install.packages("stringr")
install.packages("ggplot2")#
Install
install.packages("tm")
# for text mining
install.packages("SnowballC")
# for text stemming
install.packages("wordcloud")
# word-cloud generator
install.packages("RColorBrewer")
# color palettes
Perintah ini berguna untuk menginstall packages
yang kita butuhkan untuk sentiment analysis nanti.
Ketikkan
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
library(plyr)
library(stringr)
library(ggplot2)
library(devtools)
Perintah ini berguna
memakai package yang tadi sudah didownload.
Masukkan perintah ini
install_github("pablobarbera/Rfacebook/Rfacebook")
library(Rfacebook)
Perintah ini berguna untuk menginstall package berdasarkan link github dan
memakai package tersebut.
Untuk memakai API
Facebook kita perlu memasukkan token akses yang tadi sudah kita persiapkan
dengan perintah
fb_auth = 'token akses'
Pada twitter kita bisa mengambil post orang dengan bebas, tapi pada facebook
sekarang sudah tidak bisa, maka kita perlu mencari halaman pada facebook untuk
dilihat postingannya dengan perintah
fb_page <- getPage(page="TirtoID", token=fb_auth, n = 150,
feed = FALSE,
reactions = TRUE, verbose = TRUE, api = "v2.9")
Setelah itu kita perlu melihat hasil yang didapatkan dengan perintah
View(fb_page)

Setelah melihat hasilnya, kita perlu memilih postingan mana yang akan diambil komentarnya dan mengubahnya menjadi dataframe serta melihat hasilnya kembali. Perintahnya
fb_post <- getPost(post = '1515768312081946_2037957289863043', n=139,
token=fb_auth,api = "v2.9")
fb_post_df <-
as.data.frame(fb_post[2])
View(fb_post_df)

Setelah itu komen yang
kita dapatkan masih belum bersih dari tanda baca, kita perlu membersihkannya
dan melihat hasilnya lagi dengan perintah
comments_data <-
sapply(fb_post_df$comments.message,function(row) iconv(row, "latin1",
"ASCII", sub=""))
comments_data <-
gsub("@\\w+", "", comments_data)
comments_data <-
gsub("#\\w+", '', comments_data)
comments_data <-
gsub("RT\\w+", "", comments_data)
comments_data <-
gsub("http.*", "", comments_data)
comments_data <-
gsub("RT", "", comments_data)
comments_data <-
sub("([.-])|[[:punct:]]", "\\1", comments_data)
comments_data <-
sub("(['])|[[:punct:]]", "\\1", comments_data)
View(comments_data)

Kemudian data yang
sudah bersih tadi dapat kita analisis dan buat gambar. Caranya kita perlu
masukkan data yang sudah bersih tadi ke corpus, periksa isi dokumen tersebut
dan mengubah teks dalam data tersebut menjadi huruf kecil, menghapus angka, dan
yang lainnya dengan perintah.
docs <- Corpus(VectorSource(comments_data))
inspect(docs)
# Convert the text to lower case
docs <- tm_map(docs, content_transformer(tolower))
# Remove numbers
docs <- tm_map(docs, removeNumbers)
# Remove english common stopwords
docs <- tm_map(docs, removeWords, stopwords("english"))
# Remove your own stop word
# specify your stopwords as a character vector
docs <- tm_map(docs, removeWords, c("blabla1",
"blabla2"))
# Remove punctuations
docs <- tm_map(docs, removePunctuation)
# Eliminate extra white spaces
docs <- tm_map(docs, stripWhitespace)
Kemudian kita menganalisa kata-kata yang sering muncul pada data tersebut
dengan perintah
dtm <- TermDocumentMatrix(docs)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
head(d, 10)
Kita dapat membuat word cloud dari data yang sudah dianalisa tersebut dengan perintah
set.seed(1234)
wordcloud(words = d$word, freq = d$freq, min.freq = 1,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))

Wordcloud diatas hanya untuk
mengumpulkan kata-kata yang sering digunakan yang mana, belum mengelompokkan
apakah kalimat pada kolom komentar yang menggunakan kata-kata diatas tergolong
positif atau negatif.